


 Your new post is loading...
Your new post is loading...

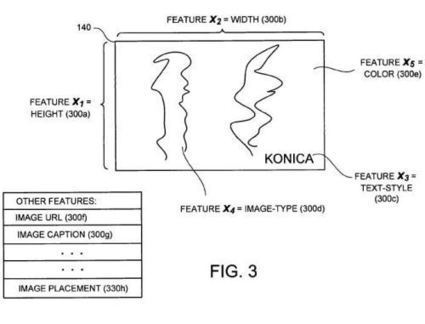

A newly granted patent describes a machine learning process that identifies features from known data sources to compare against unknown sources from very large data sets.
From the original article: "Google was granted a patent today that could be used to collect a seed set of data about features associated with different types of mushrooms, to “determine whether a specimen is poisonous based on predetermined features of the specimen.”
The patent also describes how that process could be used to help filter email spam based upon the features found within the email, or to determine whether images on a page are advertisements, or to determine categories of pages on the Web on the basis of textual features within those pages."
"This patent presents a way of examining features on a seed set of known pages, and developing comparisons of those features with features found on an unknown set to determing a classification of those pages based upon the examined features.
It also allows for the introductions of new features to be used while the classification process is ongoing."
Must-read. 8/10
Full article: http://www.seobythesea.com/2012/05/google-panda-patent/





